

Since we launched in December, all of our API request traffic to Airtable has been GET requests. Specifically, we poll their API by requesting pages of 100 records at a time.
The performance of these GET requests is good, averaging just below 600ms. The slowest 95th percentile is about 1100ms:
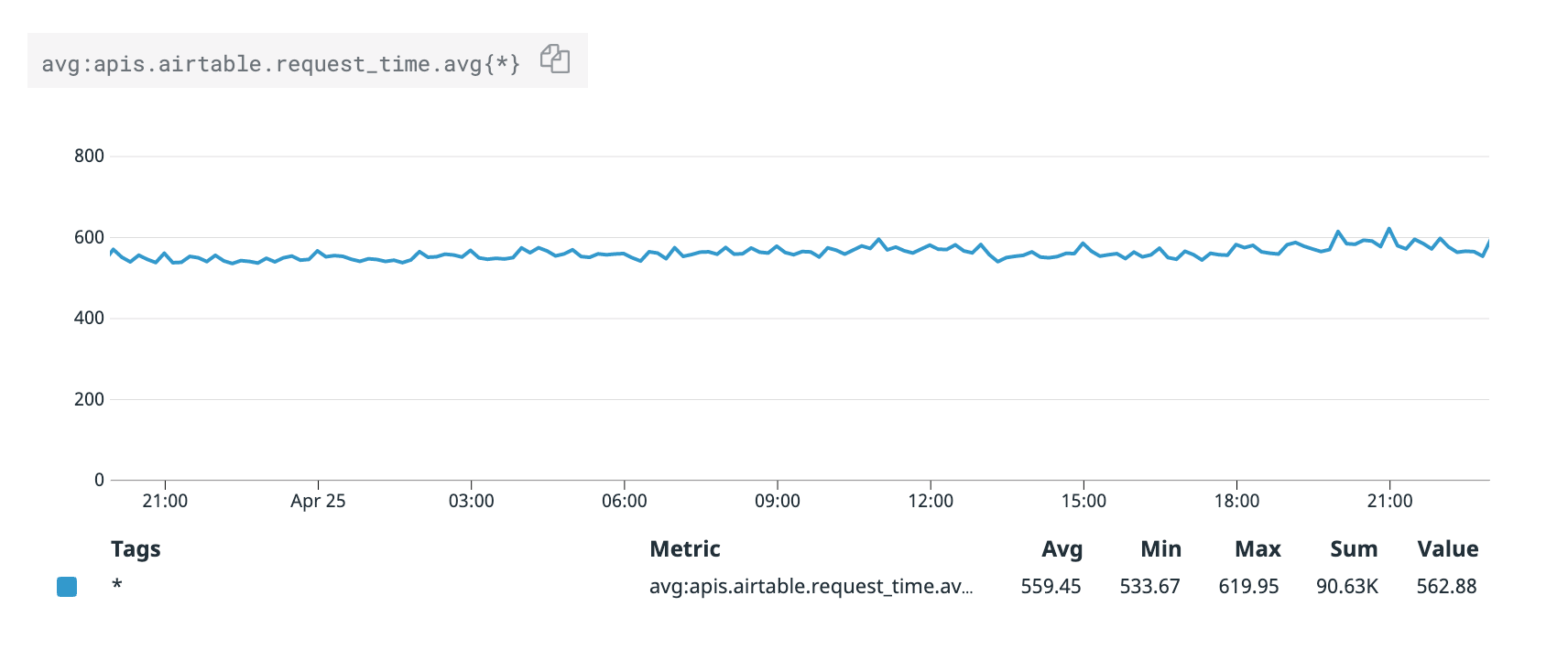
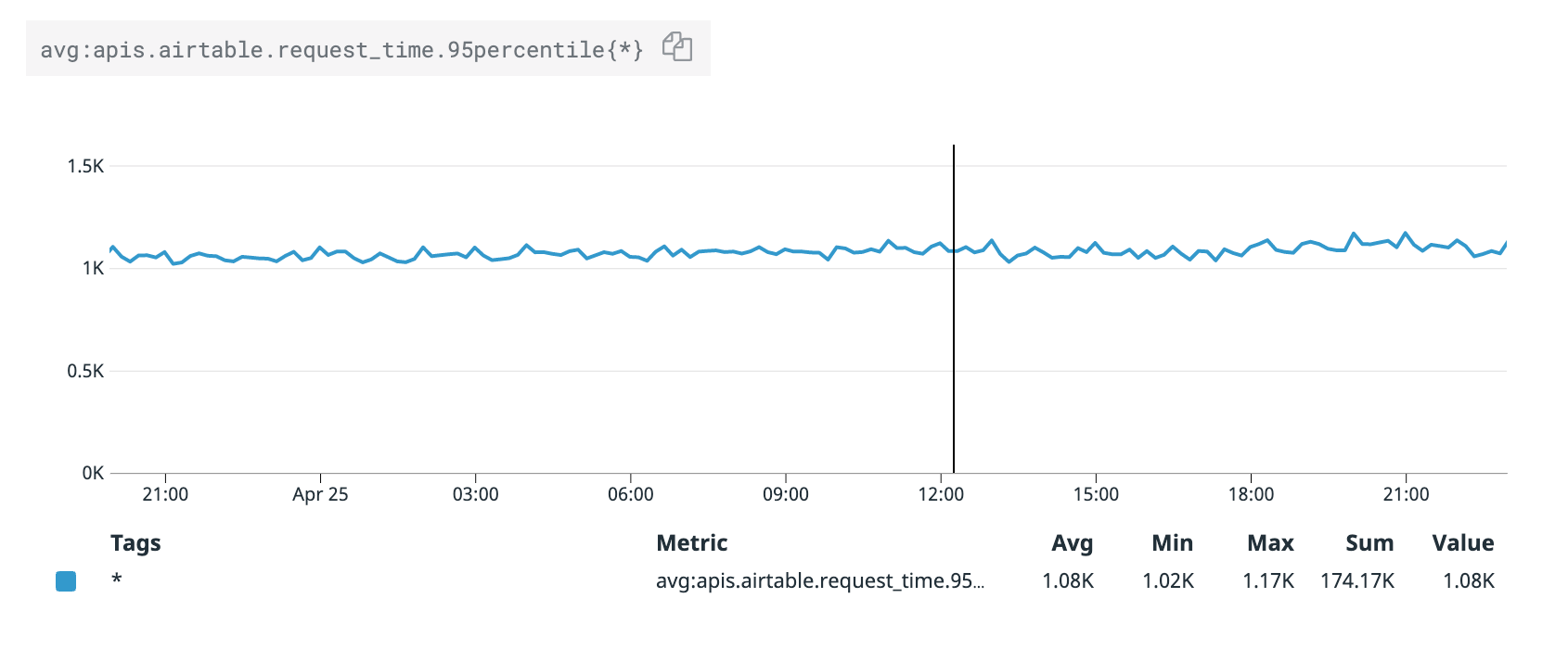
We're in AWS' us-west-2 (Oregon) and Airtable is in us-east-1 (N. Virginia). We expect that to add about 75ms of round-trip latency to each request.
At the beginning of this month, we released our proxy. Our customers make write requests through our proxy, like this:
curl -v -X POST https://proxy.sequin.io/api.airtable.com/v0/appi7vQMBr0oPikls/Main \
-H "Authorization: Bearer keyshhhhhhh" \
-H "Content-Type: application/json" \
--data '{ "records": /* payload */ }
Those writes are committed to both Airtable and their Sequin database simultaneously.
As a result, we're now starting to service Airtable API traffic that isn't just GET requests, but PATCH/POST/DELETE requests as well.
Along with these new request types, we've noted API performance statistics that seemed unusual. For example, we're working with some bases that consistently take up to 10 seconds to service all PATCH/POST/DELETE requests.
I wanted to get to the bottom of what caused writes to slow down so significantly. So I wrote up some quick benchmarks. Each benchmark you see below is the result of running a given type of request against a base at least 100 times in succession.
Testing different base sizes
The first hypothesis was the most obvious: Perhaps as a base gets larger (ie holds more records), writes get slower.
To test this, I used bases of three sizes that we already had in our account (1k, 10k, and 49k records). These bases did not have the same structure, ie they had different fields (columns). I ran my benchmarks against each base. Here's the average duration at each base size:
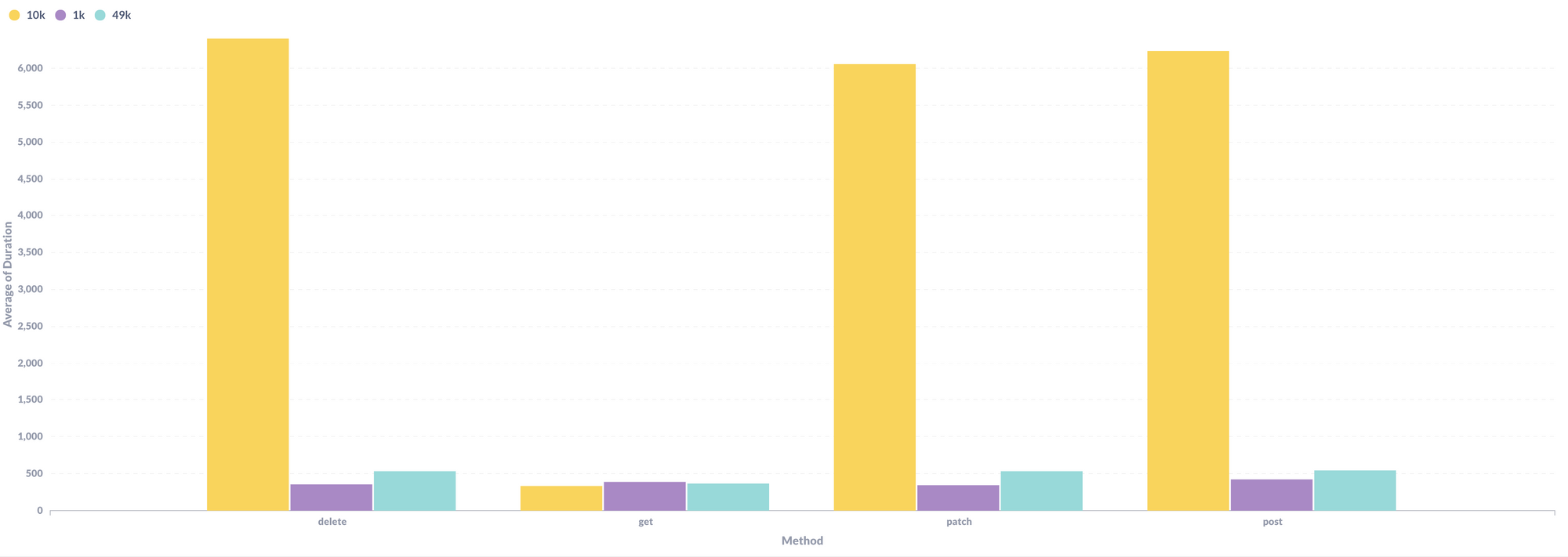
The result was a bit surprising: The average duration of write requests against the 10K base was by far the largest. All write requests to the 10k base took about the same amount of time to service. And there was no meaningful difference between the 49K base and the 1K base.
Given how similar the performance between the 1K base and 49K base is, this benchmark illustrates that the correlation between base size and the service time for writes is weak. This instead suggests that something about the fields in a base play a role.
Something is happening with the fields in the 10K base that is not present in the 1K and 49K bases.
Computed fields
It turns out that the 10k base had a lot of Formula and Lookup field types. These fields are computed. You supply a little function that Airtable runs to derive the cell value, based on other records in the base.
My next hypothesis was that these computed fields were responsible for the slowdown on writes. I began adding arbitrary formula fields to the base, but that didn't seem to make an impact. I suspected that the Pareto Principle was at work and that one or two computed fields were responsible for a majority of the latency.
So I stripped out all the computed fields in the 10k base and confirmed the slowdown for writes disappeared. Then I added back computed fields, one-by-one, until I got my first jump:
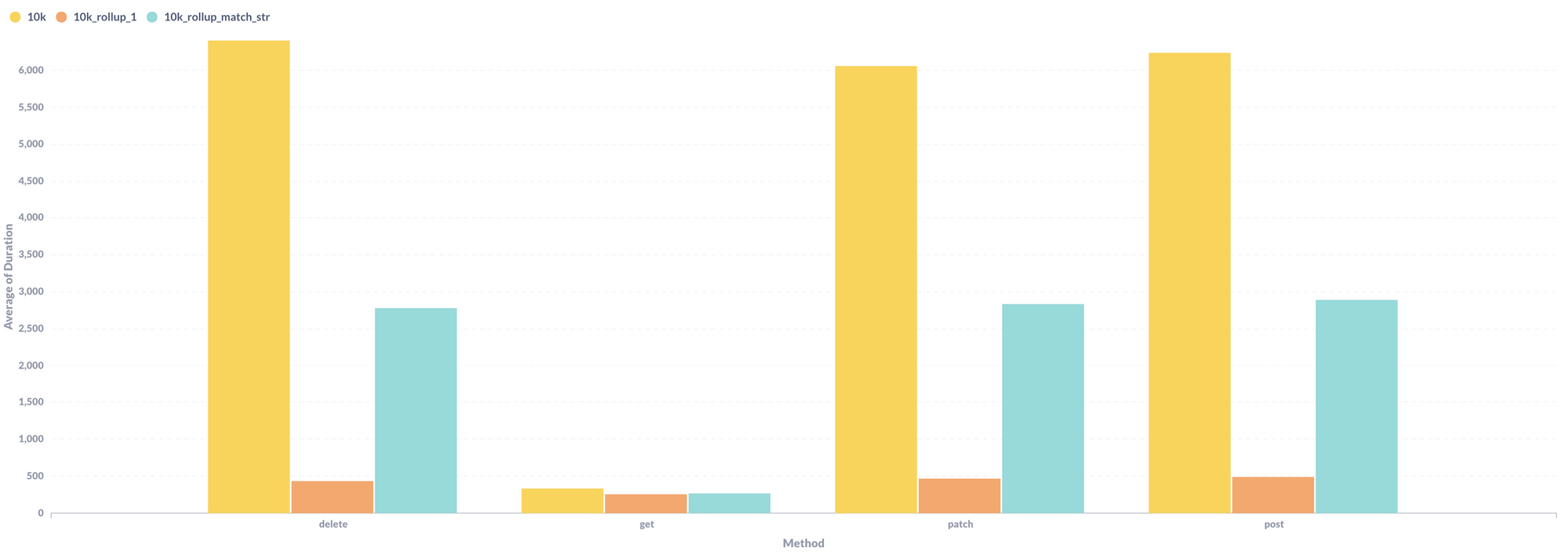
The yellow bar is the full 10k base. The orange bar is the base with all its computed fields stripped out. The turquoise bar is what I got after I added back one of the computed fields.
This base was based off a de-duplication base from the community. It has some fairly complex computed fields. Here's the computed field that tipped the scales:
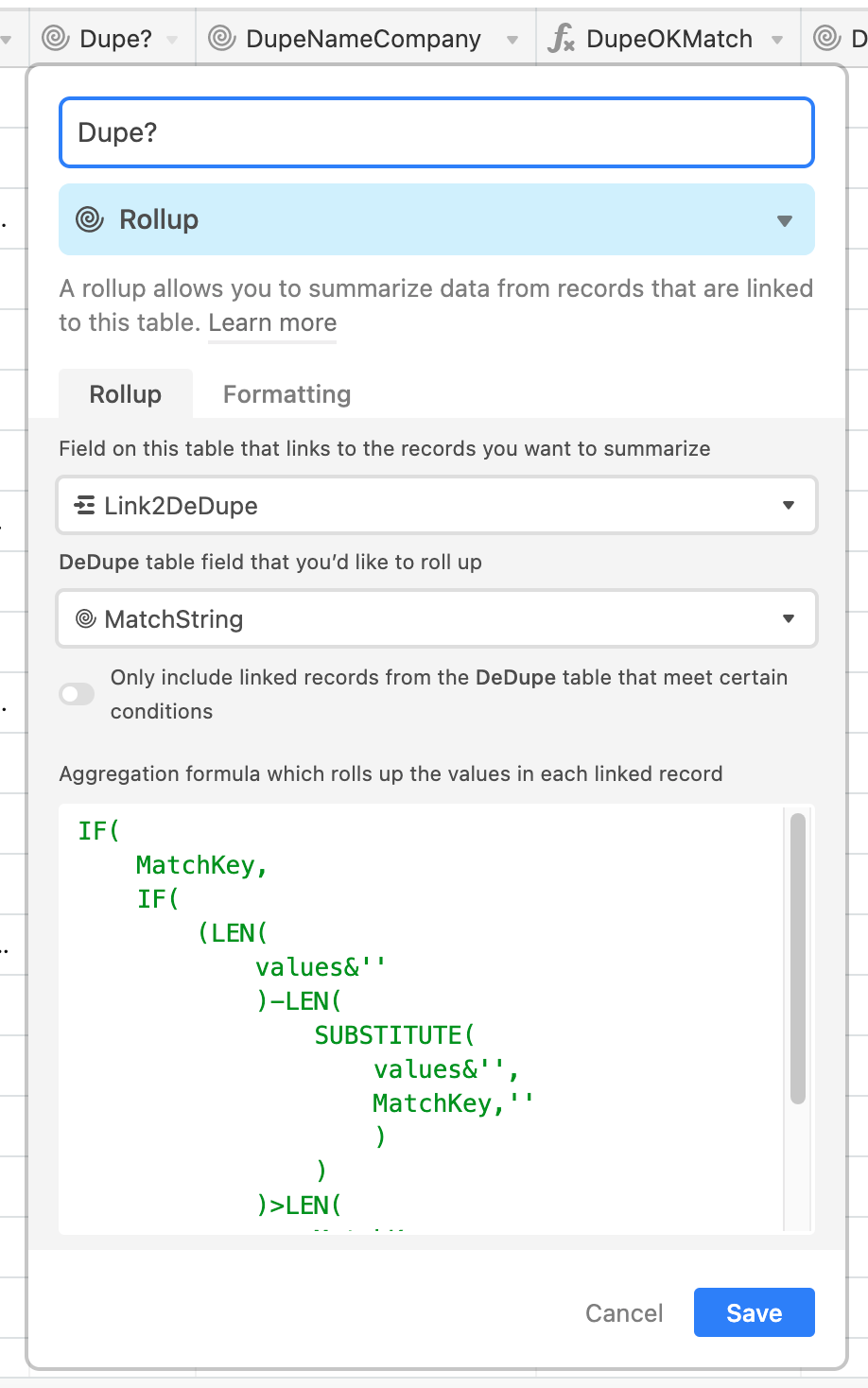
The full snippet below:
IF(
MatchKey,
IF(
(LEN(
values&''
)-LEN(
SUBSTITUTE(
values&'',
MatchKey,''
)
)
)>LEN(
MatchKey
),
1
)
)
You can see that the operation it's performing is non-trivial. But what might be more impactful than the formula itself is the fact that it's operating on another lookup field, and that field is operating on another formula field. So, to calculate a given cell value, there's a small function stack that has to be executed!
Check out the standard deviation of these results:
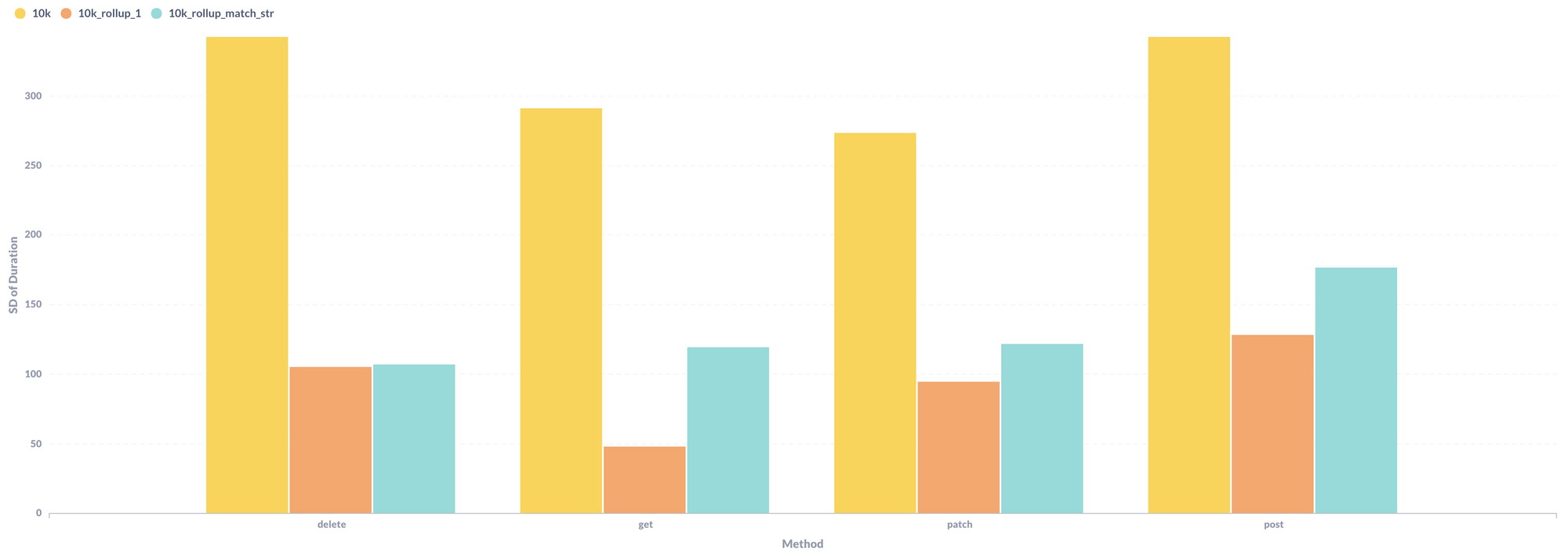
This relatively small standard deviation tells us the results are pretty consistent request-to-request. This suggests that these computed fields don't add an erratic service time. They add a consistent overhead to each and every request.
Takeaway
We can reason about what is happening here: When you create or update a record in Airtable, Airtable constructs all of its computed fields. Whether these computed fields are stored or cached anywhere is unclear. But, regardless, Airtable still needs to generate these fields because they return them to you in their API response:
200 OK
{
"records": [
{
"id": "recgm4yapfePwBTmq",
"fields": {
"ID": "00001",
"Job Title": "Building superintendent",
"First": "Deborah",
"Last": "Harris",
"Company": "Gottschalks",
"Link2DeDupe": [
"reck9Y37hBxarHHIw"
],
// ...
}
}
// ...
]
}
This means your creates/updates/deletes will only work as fast as it takes to calculate all your computed fields. (The fact that deletes take the same amount of time as creates and updates suggests that the computed fields for a base are indeed being re-calculated whenever the base is mutated.)
Now that we've isolated computed fields as the main culprit, I was still curious if there was any correlation with base size. So, I doubled the size of the 10k base with the problematic lookup field and ran the benchmarks again:
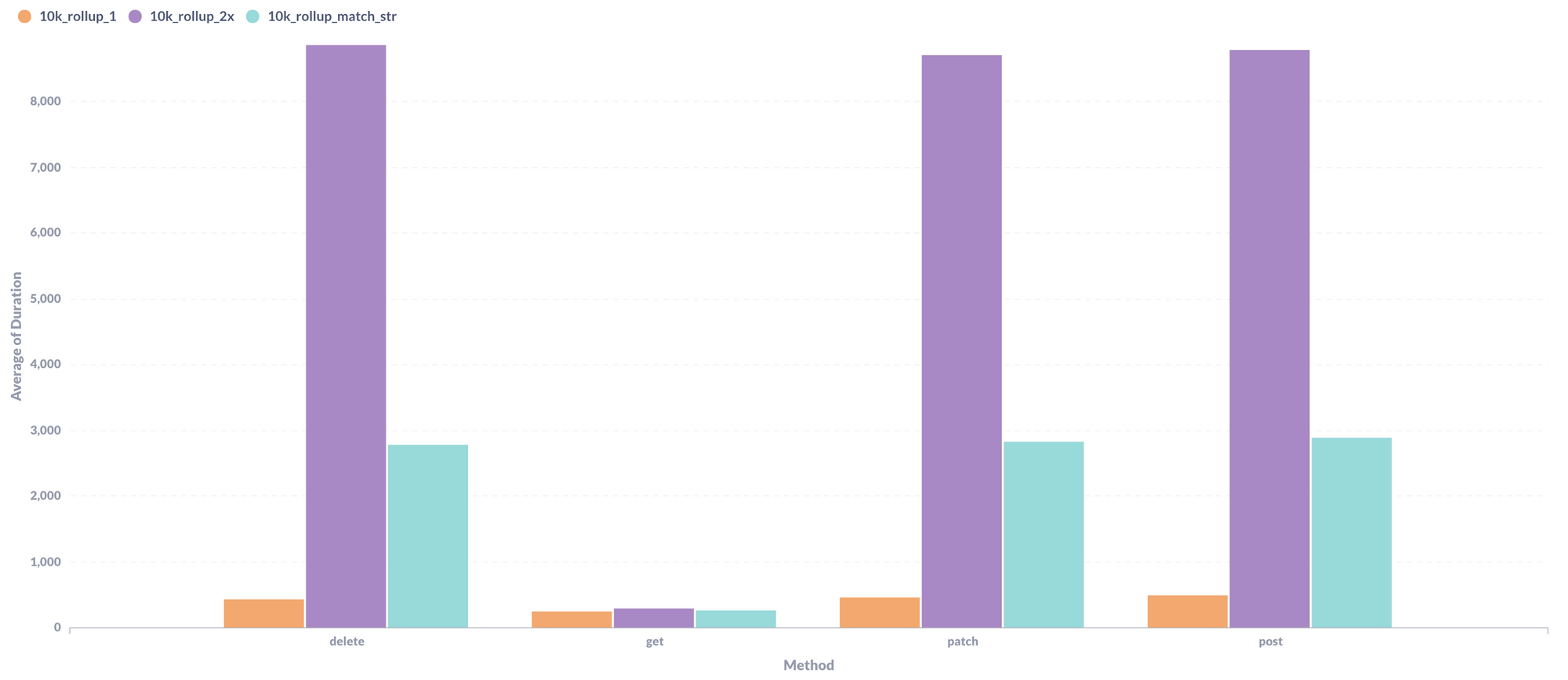
Turquoise is the base with 10k records which contains that one heavy computed field. Purple is the turquoise base, but doubled in size. Doubling the size of the base almost tripled the service time for all write requests!
So, it feels safe to draw the following conclusion:
A sufficiently complex computed field can easily increase the write time for your base dramatically. This impact is proportional to the size of your base.
This means that if your base is highly transactional (expecting a lot of reads/writes through the API), you should be mindful about how computed fields fit into your schema.
As an alternative to complex, inter-connected computed fields, you can lean on automations or scripts to populate derivative fields. Or, you can move such logic out of your Airtable base entirely.
Other notes: Outlier requests
It's worth noting that in my results, I pruned out some outlier requests. About every ~200 requests or so, I'd have one API request that would take nearly 30 seconds to complete. It is not clear to me why these occurred or what would have happened if halfway through waiting I'd canceled the request and simply tried to make a new one. (Worth future investigation.)