

We're Sequin, a Postgres CDC tool to streams and queues like Kafka, SQS, HTTP endpoints, and more. Sequin is particularly good at helping you process API records that you're syncing to Postgres.
Last updated: 11/17/2023
Webhooks are a supplement to many APIs. With a webhook system in place, System B can register to receive notifications about certain changes to System A. When a change occurs, System A pushes the change to System B, usually in the form of making an HTTP POST request.
Webhooks are intended to eliminate or reduce the need to constantly poll for data. But in my experience, webhooks come with a few challenges.
In general, you can't rely on webhooks alone to keep two systems consistent. Every integration I've ever worked on has realized this fact by eventually augmenting webhooks with polling. This is due to a few problem areas.
First, there are risks when you go down. Yes, senders typically retry undelivered webhooks with some exponential back-off. But the guarantees are often loose or unclear. And the last thing your system probably needs after recovering from a disaster is a deluge of backed-up webhooks to handle.
Second, webhooks are ephemeral. They are too easy to mishandle or lose. If you realize after deploying a code change that you fat-fingered a JSON field and are inserting nulls into your database, there is no way to play the webhooks back. Or, you might handle part of the webhook processing pipeline out-of-band with the webhook request – like the database insert. But then you risk that failing and you losing the webhook.
To mitigate both of these issues, many developers end up buffering webhooks onto a message bus system like Kafka, which feels like a cumbersome compromise.
Consider the architecture for a sophisticated webhook pipeline between two parties:
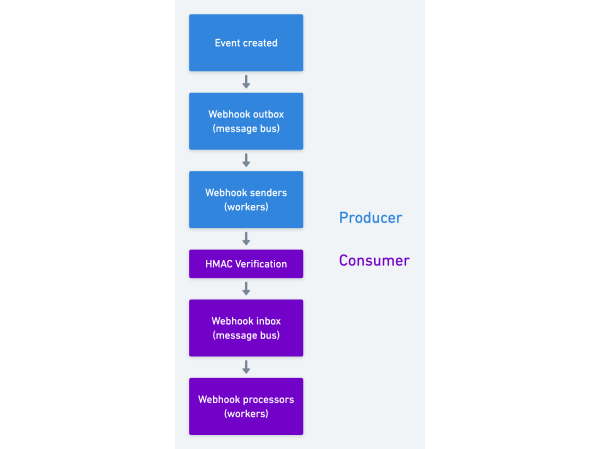
We have two message buses, one on the sending end and one on the receiving end. The complexity is apparent and the stages where things can go wrong are many. For example: On the receiving end, even if your system is tight you're still subject to sender deliverability failure. If the sender's queue starts to experience back-pressure, webhook events will be delayed, and it may be very difficult for you to know that this slippage is occurring.
Adding to the complexity, the security layer between the two is usually some HTTP request signing protocol, like HMAC. This is robust and alleviates managing a secret. But it's also far less familiar to your average developer and therefore more prone to headache and error. (HTTP request signing and verification is one of those tasks I feel one does just infrequently enough to never fully commit to memory.)
So, not only do webhooks leave you open to eventual inconsistency, they're also a lot more work for everybody.
What else can we use to keep two systems in sync, then?
The /events endpoint
For inspiration on keeping two data sets in harmony, we need look no further than databases. Consider Postgres' replication slots: you create a replication slot for each follower database, and the followers subscribe to that replication slot for updates.
The two key components are:
- The primary database keeps a log of everything that's changed recently and
- The primary database keeps a cursor that tracks the position in the changelog for each follower database
If the follower goes down, when it comes back it can page through the history at its leisure. There is no queue, nor workers on each end trying to pass events along as a bucket brigade.
APIs can follow from this model as well. Take Stripe. They have an /events endpoint that contains all creates, updates, and deletes to a Stripe account over the last 30 days. Each event object contains the full payload of the entity that was acted upon. Here's an example of an event for a subscription object:
{
"id": "evt_1J7rE6DXGuvRIWUJM7m6q5ds",
"object": "event",
"created": 1625012666,
"data": {
"object": {
"id": "sub_JgFEscIjO0YEHN",
"object": "subscription",
"canceled_at": 1625012666,
"customer": "cus_Jff7uEN4dVIeMQ",
"items": {
"object": "list",
"data": [
// ...
],
"url": "/v1/subscription_items?subscription=sub_JgFEscIjO0YEHN"
},
"start_date": 1623826800,
"status": "canceled",
}
},
"type": "customer.subscription.deleted"
},
Some important qualities:
- Each event has a
typewhich tells us what this event is. In this case, we see that a customer's subscription has been deleted. Because the full subscription payload is included, we can update our database to reflect fields likecanceled_atand its newstatusofcanceled. - Every embedded object contains an
objectfield, so we can easily extract and parse them. - The event object liberally embeds child objects, giving us a full view of everything that changed without needing to poll the API.
So, instead of listening to webhooks to keep things up-to-date, we can poll /events. We just need to keep a cursor locally, which we use in our requests to indicate to Stripe which events we've already seen.
The advantages:
- If we go down, we don't have to worry about missing webhooks. And when we come back up, we can catch up at our own pace.
- If we deploy a bug that mishandles events, no sweat. We can deploy a fix and rewind the cursor for
/events, which will play them back. - No need for a message bus on our end.
- We don't have to worry about Stripe's webhook senders delaying delivery. Speed is in our hands. The only thing between us and the freshest data is any caching at the API layer that Stripe is doing (which appears to be none.)
- We're using a simple token-based authentication scheme.
- The way we pull and process events looks the same as how we process any other endpoint. We can reuse a lot of the same API request/processing code.
On the producer side, to support /events you need to add the same ceremony around monitoring creates/updates/deletes as you'd use for webhooks. Except, instead of needing to build a delivery pipeline, you just have to insert records into an append-only database table.
On the consumer side, you'll need to setup some polling infrastructure. This is more legwork than, say, a rudimentary webhook handling endpoint that processes everything in-band. But, I bet a decent polling system is no more difficult to build than a robust webhook handling system with, for instance, a message bus. And you get a much better consistency guarantee.
Making /events even better
There is one glaring inefficiency to the /events endpoint: to keep things as real-time as possible, you have to poll very frequently. We poll the Stripe /events endpoint every 500ms per account, and have considered halving that.
These requests are light, as for all but the most active Stripe accounts the responses will often be empty. But as programmers, we can't help but reach for a way to make this more efficient.
One idea for Stripe and other API platforms: support long-polling!
In the lost art of long-polling, the client makes a standard HTTP request. If there is nothing new for the server to deliver to the client, the server holds the request open until there is new information to deliver.
In our integration with Stripe, it would be neat if we could request /events with a parameter indicating we wanted to long-poll. Given the cursor we send, if there were new events Stripe would return those immediately. But if there wasn't, Stripe could hold the request open until new events were created. When the request completes, we simply re-open it and repeat the cycle. This would not only mean we could get events as fast as possible, but would also reduce overall network traffic.
The advantage of long-polling over websockets is code reuse and simplicity. Most integrations involve some form of polling anyway, whether you are backfilling data or replaying mishandled events. The ability to switch from eg backfilling to listening for new events in real-time with a single parameter tweak is a huge win.
Which should I use?
For API consumers, if you're lucky enough to have the choice between polling /events or using webhooks, the question of which to use boils down to your consistency needs. Webhooks can be faster for getting started, especially if you only care about a few API objects. And for some workflows, it's OK if webhooks get dropped, like if you're posting a "new subscriber" announcement to a Slack channel.
But as an integration grows in importance and as the need to ensure nothing gets dropped emerges, we think polling /events is hard to beat.
For API producers, supporting /events is not only a great gift to your API consumers. /events can easily be a stepping stone on the way to providing webhooks. Your events table can serve as a "queue" for outbound work for your webhook senders. In fact, events can unlock much-needed webhook features, like allowing your webhook consumers to replay or reset the position of their webhook subscription.