

We’re Sequin. We stream data from services like HubSpot to messaging systems like Kafka and databases like Postgres. It’s the fastest way to build high-performance integrations you don’t need to worry about. We've learned a lot about what it takes to sync HubSpot, which is what this post is about.
HubSpot is the source of truth for your customer data. It's where your Sales, Marketing, and Support teams sell, market, and support your product. But that's often the rub: you need that data in your application, too.
HubSpot integrations take many forms. For instance, when a user logs into your product for the first time, you might want to create a new customer in HubSpot. When a customer purchases a new subscription, you might want to flag their HubSpot deal for Customer Success. When a deal closes, you might want to update a user's authorization in your application. In each case, a change in one system requires a corresponding change — or several — in the other. Your HubSpot data and product data are deeply intertwined.
HubSpot's API is expansive, but its limitations make these integration stories tedious. You'll need to manage rotating tokens, meter your API calls to avoid rate limits, navigate a complex relational model, and scrounge for data to make up for missing webhooks.
Sequin's solution is to sync your HubSpot data, live, to the database already at the heart of your app.
HubSpot API limitations
Like many CRMs, HubSpot places some constraints on its API to ensure its service is reliable, secure, and proprietary. While I understand the purpose of these constraints, a quick word of caution to my fellow developers as you embark on an integration.
First, you'll need to carefully manage your API usage. Miscount and you'll see a couple (or hundreds) of 429 - RATE LIMIT errors in your logs. Even moderate API use is enough to exhaust either HubSpot's daily request limit or their ten-second maximum "burst" rate.
You'll also need to navigate HubSpot's associations model for object relationships. To update or retrieve one customer record, you may need to make five nested API calls to the search, contacts, associations, companies, and deals endpoints. Have a couple of customers to pull? Prepare for another 429!
And for many integrations, you'll want HubSpot to notify you about changes — say, when a new support ticket is filed. Too bad! HubSpot's Webhooks API is limited to Contacts, Companies, Deals, and Conversations. To detect when data changes in HubSpot and then trigger some business logic, like an email, you'll need to poll continuously for updates... and handle more 429 errors!
Of course, the API works as advertised. None of those limitations are insurmountable, given time and careful monitoring, but you can avoid them entirely by syncing your HubSpot data to your database. Let's explore this approach.
Why sync HubSpot to Postgres
Transforming the HubSpot API into a Postgres database gives you more options to build and iterate.
With a sync, you can manage your HubSpot API quota in one place, trading quota utilization for sync latency. Using /search endpoints, you can limit your requests to objects that've changed, reading their updates in pages of 100 objects at a time.
With just a third of your quota allocated to reads you can keep at least 20 objects in sync with just a minute or less of latency.
A sync separates the process of retrieving data from querying the data. Simple SQL queries can return a complete customer record, joined across several tables, and deliver it at a production-ready pace — much faster than the five sequential API calls that'd be required to produce the same joined record. Unsure what data you need? You're free to experiment on SQL data without impacting your API quota.
Your team can use their favorite database tools to work with HubSpot just as they'd work with any other application data. Internal tools, reports, killer features; the sky's the limit.
What's the best way to build and maintain a sync between HubSpot and your database?
Building a HubSpot to Postgres sync
Building a sync with the HubSpot API is a multi step process. Here is a high level overview of the system:
Authentication and Token Management
With any integration, you'll need to authenticate your requests to the HubSpot API using OAuth access tokens (since API keys are now deprecated).
You'll first need to create a developer account, a private app for your sync, and then generate a token with an OAuth handshake:
const hubspotClient = new hubspot.Client({});
const token = "token";
try {
const apiResponse = await hubspotClient.oauth.accessTokensApi.getAccessToken(token);
console.log(JSON.stringify(apiResponse.body, null, 2));
} catch (e) {
e.message === 'HTTP request failed'
? console.error(JSON.stringify(e.response, null, 2))
: console.error(e)
}
HubSpot access tokens are short-lived, so you'll then need to check the token's expiration and refresh as needed:
const hubspot = require('@hubspot/api-client');
const hubspotClient = new hubspot.Client({});
const token = "token";
try {
const apiResponse = await hubspotClient.oauth.refreshTokensApi.getRefreshToken(token);
console.log(JSON.stringify(apiResponse.body, null, 2));
} catch (e) {
e.message === 'HTTP request failed'
? console.error(JSON.stringify(e.response, null, 2))
: console.error(e)
}
Keep in mind that generating and refreshing access tokens counts against your API rate limit.
Quota Management
The HubSpot API has both a "burst" and "daily" API limit. These limits increase if you purchase a higher limit or enterprise plan.
| HubSpot product tier | Requests per app per 10 seconds | Requests per account per day |
|---|---|---|
| Free or Starter | 100 | 250,000 |
| Pro or Enterprise | 150 | 500,000 |
| Any, with API Limit Increase add-on | 200 | 1,000,000 |
Keep the small print in mind as well! The /search endpoint (which you'll use throughout your sync) is subject to an entirely different rate limit of 4 requests per second per authentication token, sixty percent less than the rest of the API.
When you hit the rate limit, you'll receive a 429 error response. To keep track your quota, check these properties in the HEADER of HubSpot's API response:
| Header | Description |
|---|---|
X-HubSpot-RateLimit-Daily |
The number of API requests you are allowed to make per day. |
X-HubSpot-RateLimit-Daily-Remaining |
The number of remaining requests you can make today. |
X-HubSpot-RateLimit-Interval-Milliseconds |
The time period that is monitored to cap API bursts. A value of 10,000ms = 10 seconds. |
X-HubSpot-RateLimit-Max |
The number of API requests allowed during the burst period. If the RateLimit-Interval is 10 seconds, and the RateLimit-Max is 100, then you can make at most 100 requests per 10 seconds. |
X-HubSpot-RateLimit-Remaining |
The number of remaining API requests in the current RateLimit-Interval. |
To stay within the usage limits, it's best to implement a quota management system to throttle your API calls. In addition to some helpful examples in the HubSpot developer forums, you'll find existing libraries you can use to manage your quota. Remember, you'll need to measure your /search API usage separately.
Backfill: paginate each endpoint
With authentication and quota management in place, you can begin to paginate through each API endpoint to load your historic data into your database.
For instance, to backfill contacts you'll call the list endpoint:
const hubspot = require('@hubspot/api-client');
const hubspotClient = new hubspot.Client({"apiKey":"YOUR_HUBSPOT_API_KEY"});
const limit = 100;
const after = undefined;
const properties = undefined;
const propertiesWithHistory = undefined;
const associations = undefined;
const archived = false;
try {
const apiResponse = await hubspotClient.crm.contacts.basicApi.getPage(limit, after, properties, propertiesWithHistory, associations, archived);
console.log(JSON.stringify(apiResponse.body, null, 2));
} catch (e) {
e.message === 'HTTP request failed'
? console.error(JSON.stringify(e.response, null, 2))
: console.error(e)
}
As you retrieve contacts from each page, store the pagination_id in case the process running the backfill should fail and you need to restart the process.
Sync: polling and cursors
With the historic data loaded into your database, you'll then poll the search endpoint for newly created or updated HubSpot objects by using the hs_lastmodifieddate property to filter and sort records.
curl https://api.hubapi.com/crm/v3/objects/contacts/search?hapikey=YOUR_HUBSPOT_API_KEY \
--request POST \
--header "Content-Type: application/json" \
--data '{
"filterGroups":[
{
"filters":[
{
"propertyName": "hs_lastmodifieddate",
"operator": "GTE",
"value": "2023-02-28 18:12:06.469752"
}
]
}
]
}'
You'll store the most recently synced hs_lastmodifieddate as a cursor for each object type to ensure you only retrieve newly created or updated contacts, deals, etc. from their respective /search endpoints.
Keep in mind that
/searchendpoints are rate-limited to 4 requests per second per token.
Handle: eventual consistency
HubSpot's /search endpoints are (or at least appear to be) not strictly consistent. It can take several minutes for a newly created or updated object to appear in the /search endpoint. Especially if that object is being rapidly updated by users in the HubSpot client (for instance, moving a deal through multiple stages in quick succession).
This means that an object or property can be updated in HubSpot precisely at noon GMT, and you can request that object at noon plus 1 second GMT with your cursor (i.e. hs_lastmodifieddate) set to search for objects updated at noon GMT, but the object won't return in the search. Instead, that object might not appear in the search for several minutes.
To avoid missing updates entirely, you'll need to account for this eventual consistency by creating a process that tries to catch and sync objects that don't immediately return in your /search query by searching further into the past. Here are the components of the process:
- Create another process that uses
hs_lastmodifieddateas the search property. - Set
hs_lastmodifieddateto approximately ten minutes before the present. - Retrieve the results, and identify objects and properties that were missing in your primary search job.
- Load these newly found objects and properties into your database.
You'll need to run this kind of "eventual consistency" job for each HubSpot object type you wish to sync.
Detect: deletes
With your backfill, polling process, and eventual consistency job - every new and updated object in HubSpot will sync to your database. Now, you need to detect deletes - which requires one more process in your sync architecture.
You can detect deletes on some standard objects (COMPANY, CONTACT, DEAL, LINE_ITEM, PRODUCT, and TICKET) by calling the LIST endpoint for that collection and setting the query parameter archived=true.
Here is a CURL example for the contacts endpoint:
curl --request GET \
--url 'https://api.hubapi.com/crm/v3/objects/contacts&archived=true&hapikey=YOUR_HUBSPOT_API_KEY'
This endpoint will return all the archived/deleted objects for the given object collection. To avoid waisting time (and quota) constantly sweeping through all the deleted objects, you can store a "backstop" cursor (i.e. the last-archived object you processed) and then sweep backward through time until you hit the backstop. If a sweep reveals newly-archived objects, update the backstop to the latest timestamp among them.
While this approach will work for standard CRM objects, custom objects require another backfill job to detect and remove deleted records from your database.
Sync: relationships
Creates, updates, and deletes are now syncing. But you aren't done yet. You know need to handle associations - a.k.a the relationships in your CRM.
When an object's associations change, the object isn't considered modified – its hs_lastmodifieddate, which surfaces objects in /search job results, doesn't budge. Moreover, even if you could use /search to detect a new association, the associations themselves aren't available in the search results.
Instead, you'll need to detect new, updated, and deleted associations by polling through every page of the LIST associations endpoint"
curl --request GET \
--url 'https://api.hubapi.com/crm/v4/objects/contact//associations/?limit=500' \
--header 'authorization: Bearer YOUR_ACCESS_TOKEN'
You'll need to create a polling job of this kind for one side of each association pair.
Manage: schema migrations
HubSpot supports both custom objects and custom properties. As HubSpot administrators create, update, or delete these objects, the shape of the API response will change. You'll want to handle schema migrations to accommodate these changes.
The complete system
You'll build several distinct services to sync HubSpot to your Postgres database:
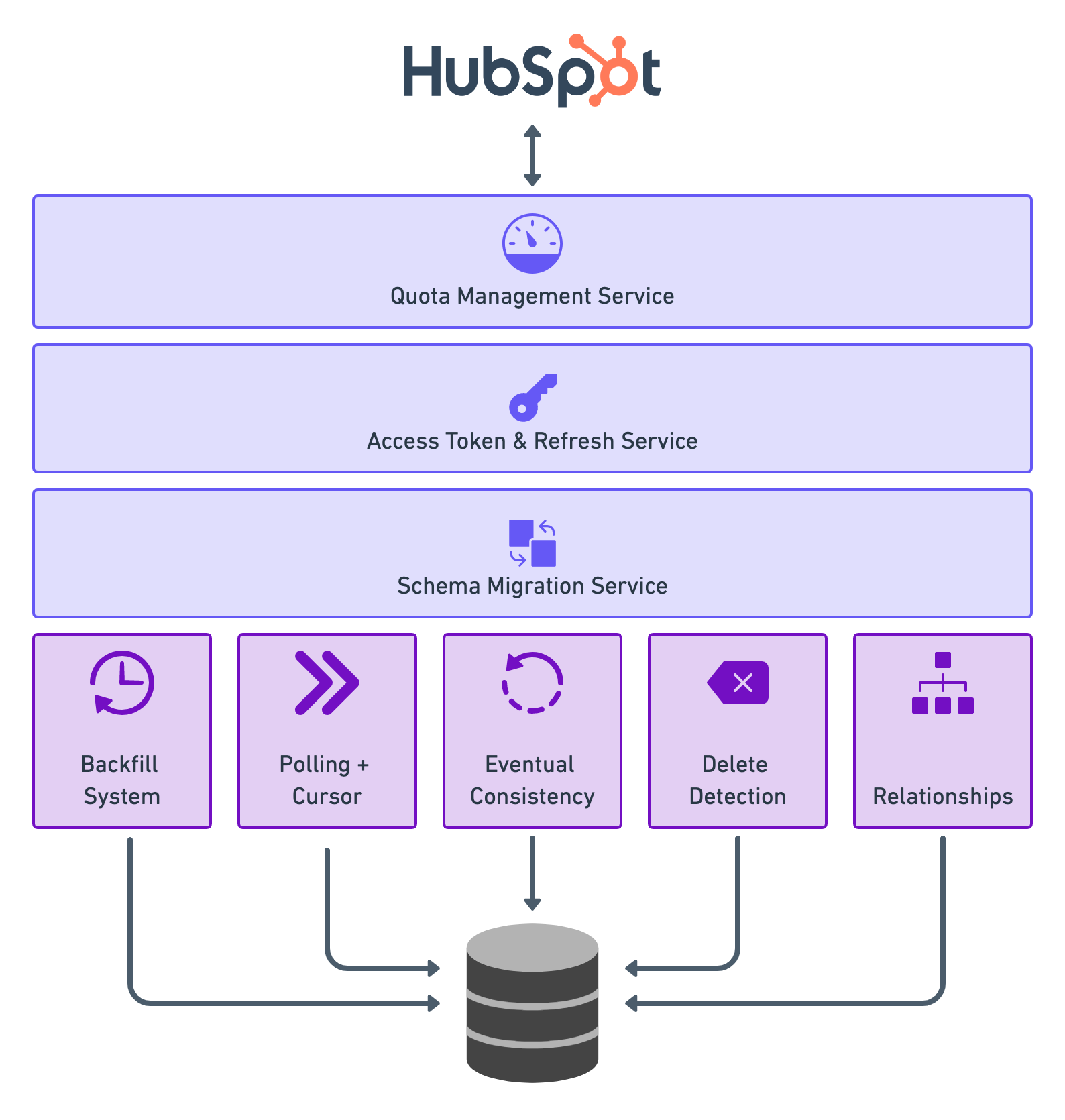
In the end, it's a system you can reliably use to query the data you need when you need it, with Postgres niceties like PG_NOTIFY to trigger business logic when HubSpot entities change while avoiding 429 status codes.
Getting a HubSpot to Postgres sync
Alternatively, skip all this hassle with Sequin.
We're a completely managed service that goes to extreme lengths to sync HubSpot to your Postgres database in real-time. We've done all the heavy lifting: managing tokens, enforcing rate limits, backfilling existing data, and syncing all new and updated objects to your database as they change.
Here are the steps for syncing HubSpot to your Postgres database using Sequin:
(1) Create a Sequin account: Go to https://app.sequin.io/to signup and create an account.
(2) Connect your HubSpot account: Create a new HubSpot sync, and generate a token for Sequin by entering your HubSpot credentials:

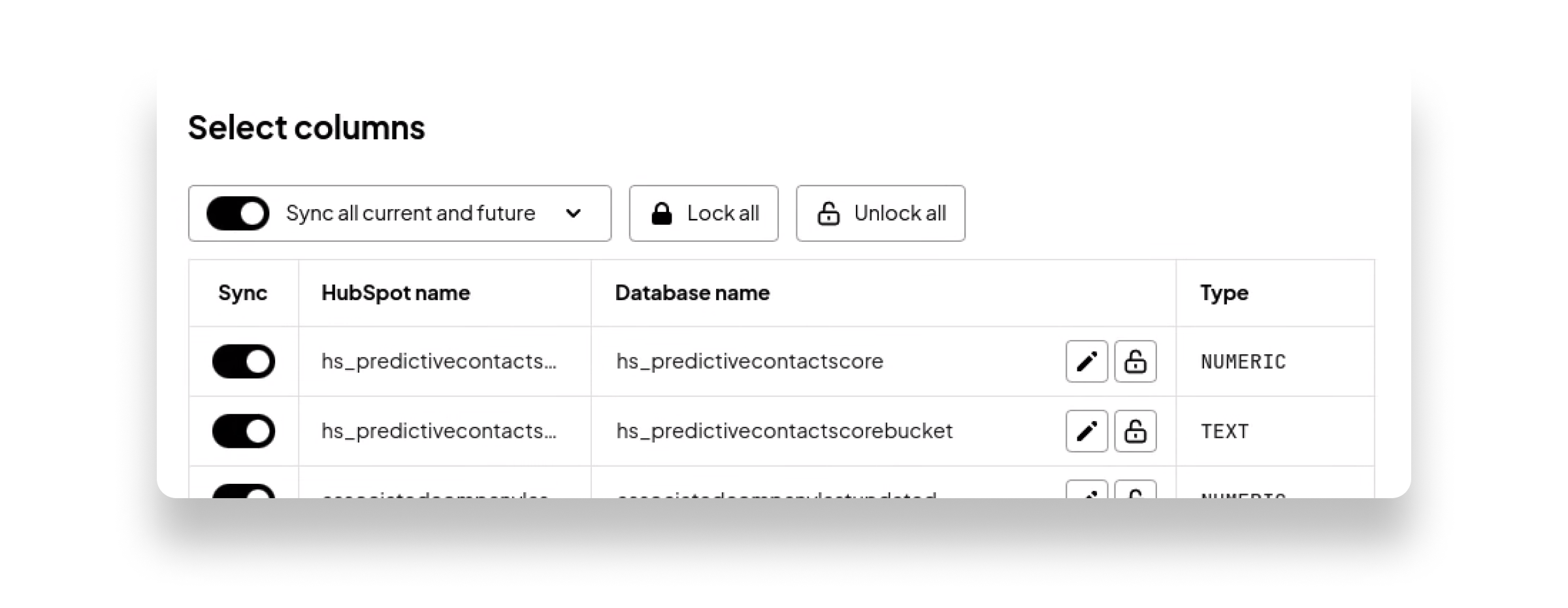
(3) Select the objects and properties to sync: Pick the objects and properties you want to sync — Sequin supports custom objects and properties out of the box. Importantly, you can edit and lock the column names in your database to ensure your SQL queries don't break when properties are renamed in HubSpot.
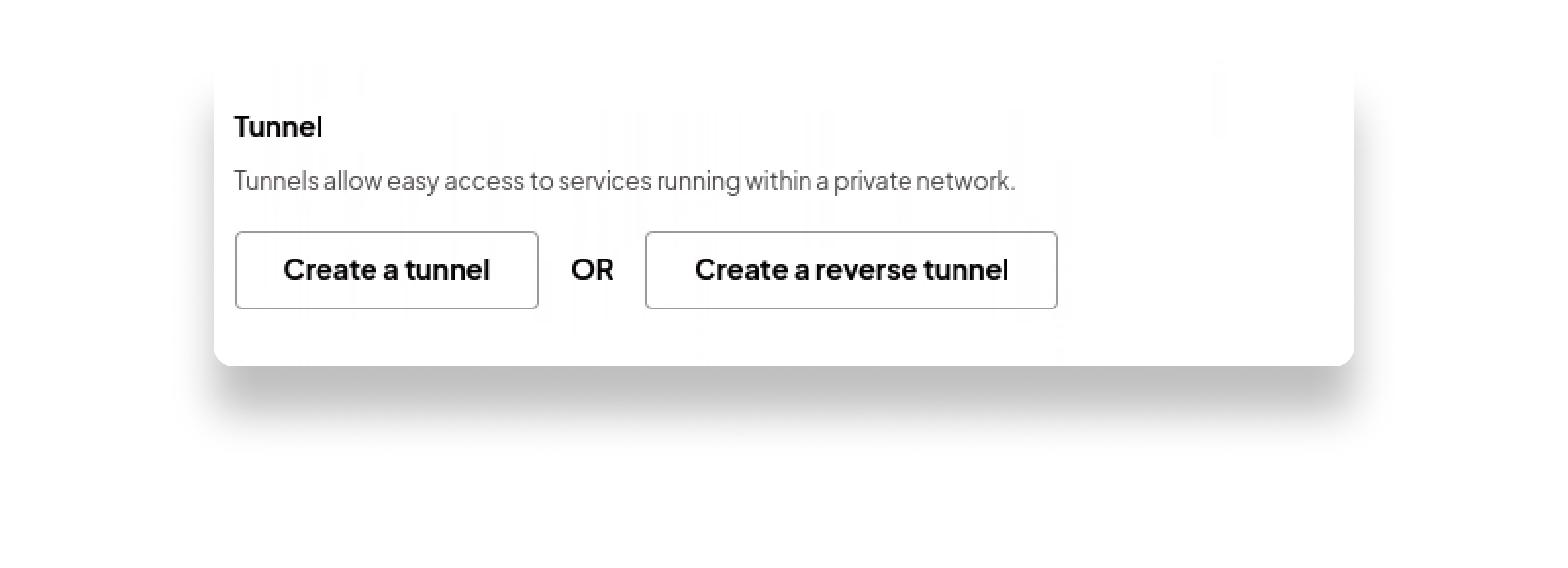
(4) Connect your database: Connect to your Postgres database (we support tunneling and VPC peering) or simply click "Start" to begin syncing your data to a Sequin-hosted demo database.
(5) Sync: Sequin will persistently sync your HubSpot data to your database in real time. As your integration evolves, you can return to the dashboard and click to sync additional tables and columns.
Next steps
Every API has quirks. Setting up a sync between HubSpot and your Postgres lets you work around these limitations, but generates some additional complexity.
We're building Sequin to help you skip the limits of the API and skip the tedium of writing all this glue code.