

We’re Sequin. We stream 3rd-party API data (e.g. Salesforce, AWS) to NATS. You can start streaming data to NATS in just 2 minutes.
We recently adopted NATS at Sequin. NATS is an open-source messaging system. At its core, NATS provides publish-subscribe messaging, but has expanded to enable other features. It has a request/reply mechanism which you can use for service-to-service communication (in lieu of HTTP APIs). And it now includes a persistence layer which means it can on workloads you'd normally turn to Kafka for. The project is supported by the CNCF.
What follows is some quick first impressions:
We like the simplicity (it's all pub/sub)
From the beginning, NATS has been a pub/sub system. While it does a lot more than pub/sub now, all other features are built on its pub/sub primitives. This makes for a simple and predictable protocol.
If you were writing your own NATS client from scratch, this is how you'd publish a message:
PUB FRONT.DOOR 11␍␊Knock Knock␍␊
This follows from the syntax:
PUB <subject> [reply-to] <#bytes>␍␊[payload]␍␊
(The ␍␊ (or 0x0D0A) is how NATS terminates protocol messages.)
It makes sense that pub/sub is the foundation for NATS; it's the most basic way for two systems to communicate. It's completely async and ephemeral. Publishers publish to topics and subscribers subscribe to them. No one needs an address, just subjects that they publish or subscribe to.
On top of pub/sub, NATS has a request/reply mechanism. The "request" is just a pub, except it includes a special handle that tells the responder where to reply (the reply-to part above). The NATS client subscribes to the reply-to and blocks after publishing, awaiting a reply.
If there are no responders available, you can have your request wait until a responder gets to it for some timeout. Or, you can have your request fail immediately.
With request/reply, you have a few more guarantees over basic pub/sub. Communication is synchronous, and the requester can know if a responder handled its request.
A few years ago, NATS took it even further with JetStream. JetStream is NATS' persistence system. A JetStream stream subscribes to a subject. It stores messages published to that subject. You can configure a stream to store messages only briefly or forever.
JetStream consumers allow you to process messages on streams using familiar semantics (think Kafka consumer groups). This gives you at least once delivery guarantees, or exactly once semantics if you use message deduplication and double acks.
The neat part is that communicating with a JetStream stream is just like communicating to any other system connected to NATS. You publish to a subject to send a message to a stream. Consumers can send a request to get messages from a stream.
Subjects (route on read)
What initially drew us to NATS was its subjects.
Subjects in NATS are dot-separated:
linux.debian.packages.xz
Wildcards give you some great expressive capabilities to specify what you want to subscribe to.
For example, a consumer can subscribe to all broadcasts about Debian packages like this:
linux.debian.packages.*
Or subscribe to any updates across distros for the xz package like this:
linux.*.packages.xz
Or subscribe to all Debian updates broadly:
linux.debian.>
While the * matches a single token, > matches one or more tokens. So, that last subscription will match any subject that begins with linux.debian..
The way we like to think about it: a lot of topic-based systems have you route on write. You need to figure out which topic to route a message to (and therefore which downstream consumers you want to see it). With NATS, you instead find yourself routing on read. When publishing, you use rich subject patterns. Then, as you add consumers to your system, you can have consumers pattern match to consume the things they care about.
This means you'll rarely have a consumer burning through a message queue full of irrelevant messages.
JetStream is full of features
JetStream is feature-rich. We've been very pleased with how finely we can tune streams to meet our needs.
For example, one of our streams is a record stream. The record stream contains the latest version of every API record we sync. When we detect an update to an API record, we want to evict the old version from the stream and append the latest version to the end of the stream. This means that workers won't duplicate work (processing a record that's already out-of-date). And that we can eliminate a class of possible race conditions for our customers.
With NATS, it was easy to express this behavior. We configured a stream with the following properties:
MaxMsgsPerSubject=1Discard=oldMaxAge=-1
This tells NATS:
- For any given subject, keep only one message. We give each record a unique subject, so this means the stream will only contain one message per record.
- When a new message is written to a subject, discard the old one.
- Keep messages around indefinitely.
While you can setup a compaction strategy in Kafka to keep only one message per key around, it doesn't behave quite the same way. There's no telling when Kafka will evict the old message. With NATS, it happens on write, so the record will never be in the stream twice.
The nats CLI is great
NATS has a great CLI. It's handy for setting things up or testing functionality while developing.
Here's an example of using the NATS CLI to publish a message:
$ nats pub linux.debian.packages.xz '{ "status": "compromised" }'
13:49:56 Published 27 bytes to "linux.debian.packages.xz"
You can subscribe to messages too. The NATS CLI will spit out messages as they're received:
$ nats sub linux.debian.packages.*
13:49:37 Subscribing on linux.debian.packages.*
[#1] Received on "linux.debian.packages.xz"
{ "status": "compromised" }
If you're working with NATS, I definitely recommend getting a little familiar with the CLI. It's often much faster than trying to run tests or debug using your programming language + SDK.
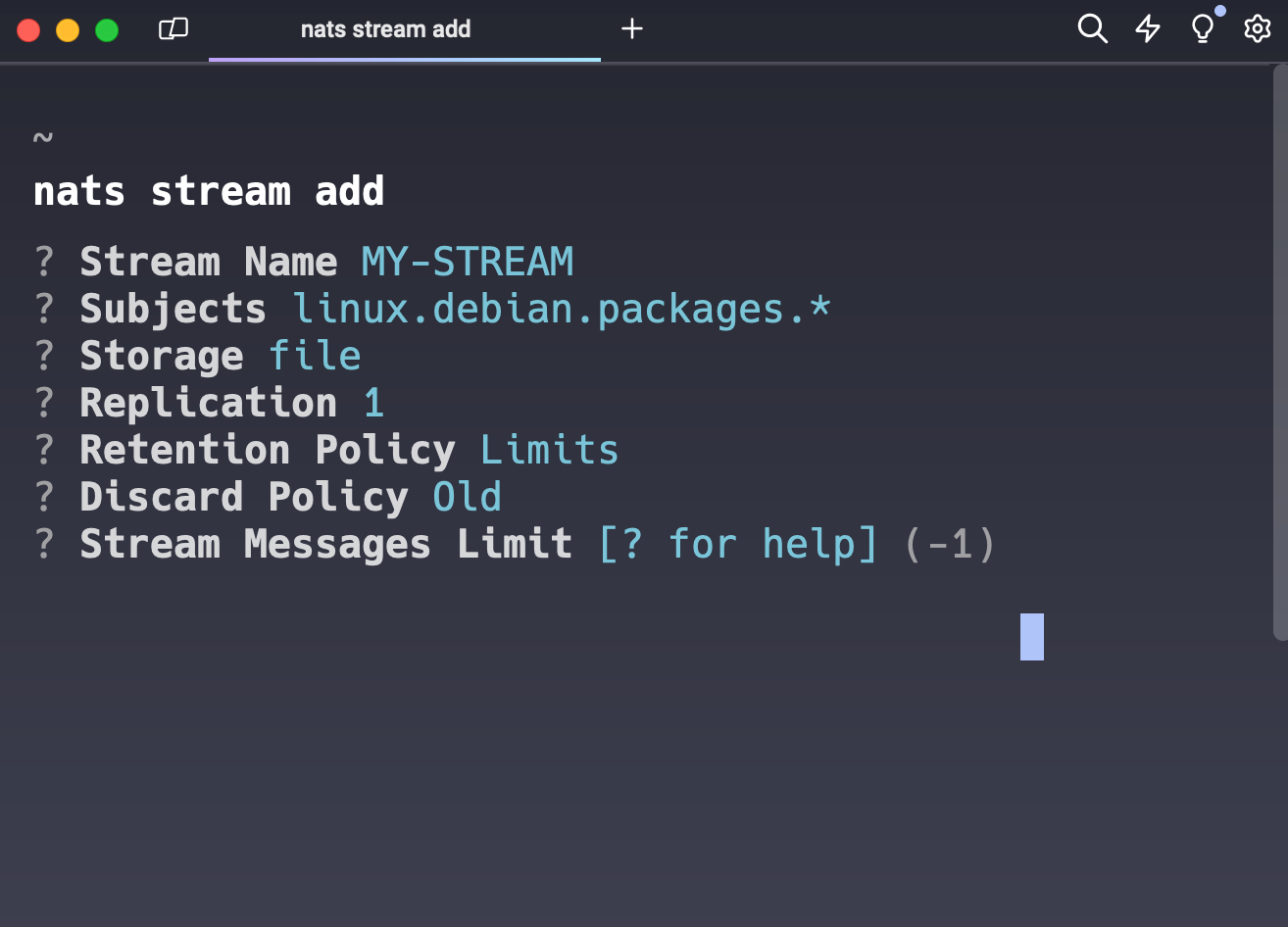
When setting up things like JetStream streams, there are a lot of options to consider. Fortunately, the NATS CLI has walkthroughs for settings, and has help text available for each option:
Can NATS do everything Kafka can do?
So far, the answer seems to be "yes." Though NATS doesn't quite match up to Kafka's partitioning paradigm.
NATS has consumers, which are like Kafka's consumer groups. But NATS' consumer mechanism is partition-less. You can have many worker instances processing messages for a given consumer at once. Message processing is non-deterministic: there is no guarantee that two sequential messages published on the same subject are going to be distributed to the same subscriber.
This is fine, except in instances where you need guaranteed ordering.
Let's say you're processing Stripe subscription updates. Sub A updates to a value of $50, but then it's updated again right away to $100 (Sub A'). If those messages are not guaranteed to be delivered to the same subscriber (i.e. the same worker instance), you have a race condition.
This is different from Kafka. In Kafka, you specify the number of partitions for a given topic. Each message is deterministically routed to a partition based on its key. Kafka guarantees ordering for a given key because only one worker instance can actively process messages for a partition at a time. To scale, you scale up partitions and workers.
So, what if you need guaranteed ordering for a given NATS consumer, but are hitting scaling limitations using a single worker instance?
NATS lets you perform deterministic subject token partitioning. So, if you're publishing messages to NATS following this pattern:
apis.stripe.subscription.{subscription_id}
You can have it use the subscription_id to deterministically append a partition number to the end like this:
apis.stripe.subscription.{subscription_id}.1
apis.stripe.subscription.{subscription_id}.2
...
You can then have different worker instances work each partition. With settings like MaxAckPending, you can prevent multiple workers from processing messages from the same consumer simultaneously (for instance, when cycling workers during deploys).
So, one way to think about it is that NATS starts with a flexible, high-throughput paradigm. But you can configure it as needed to provide different guarantees, like strict ordered message processing. Whereas Kafka comes out-of-the-box much more opinionated.
The one rub is that, as far as I can tell, partitioning in NATS requires more coordination.
In Kafka, partitions are "auto-balanced" among a consumer group based on the number of worker instances that are connected. So if you have 10 partitions but only 5 worker instances are connected, they'll each be assigned 2 partitions.
In NATS, each subscriber will need to be configured to subscribe to a particular partition. There is no "intermediary" between each subscriber and the available partitions like there is in Kafka. So, if you have 10 partitions and half your worker instances disconnect unexpectedly, the remaining workers will be none the wiser.
Conclusion
NATS has been a joy to work with. While we previously relied on various AWS services like SNS, SQS, and MSK, we like the ergonomics of NATS way more. Just like Redis and Postgres, we can easily run NATS in local dev. And we don't need to stub it out in test.
We're still exploring how far we can take it. For example, we think its request/reply mechanism will allow us to side-step clustering our Elixir nodes. We'll update as we learn more!