

We're excited to announce we've added support for Stripe to Sequin! Now you can get a replica Postgres database with all your Stripe data, synced in real-time. It’s like having row-level access to your data in stripe_prod.
Below, I'll discuss the general philosophy behind our company and touch on some of the details of Stripe's API that made working with it really great:
Reading data
API reads are way more difficult than database reads. Every API has its own pagination rules, rate limits, and auth/refresh schemes. APIs can go down or return an unknown set of errors.
Your code has to handle all of this.
Little things add up: Perhaps the API doesn't support the query you want to make, so you have to make a few subsequent calls. Later, you get complaints from customers about performance, so you cache a subset of the data. But now you have to worry about cache invalidation, so before you know it, you're on the third answer of a StackOverflow post trying to get HMAC verification for your new webhook handler working.
Ultimately, API providers are just building HTTP query abstractions over their database. But each of these interfaces are unique, and you have to learn them. And HTTP query param implementations can never match SQL in power. In fact, they rarely come close.
So why does every platform offer an HTTP API vs direct access to their databases? There are two primary reasons:
- Abstraction: A provider can "hide" underlying data model changes from API consumers.
- Access control: They need to make sure you only see data that belongs to you!
When dreaming up Sequin, we realized that you can accomplish both of these goals with a database. In fact, the database is an amazing platform for data interchange: Postgres is incredibly well-supported, the database enforces a strong schema that is easily introspected, and access controls are baked-in.
Once data is in a database, it feels "native." With SQL, you can query it just about any way you like. You can plug the data right into a variety of tools, from ORMs to internal tool builders. Databases are highly available and high throughput, so you can get rid of retry or pagination logic. And you can do things you'd never dream of doing with an HTTP integration, like backups, snapshots, or auditing.
Supporting Stripe
Airtable was the first platform we built support for. Stripe's API couldn't be more different from Airtable's. Here are some of the big features of Stripe's platform that made a real-time replica database possible:
Support for "events" or webhooks
The /events endpoint contains all creates/updates/deletes of your Stripe data. This is a critical endpoint for our implementation, and we wish more API providers had something like this. Thanks to this endpoint, we didn't even need to build out webhook handling. Our syncing infrastructure can just repeatedly poll this endpoint (>1x/second) to keep our data up-to-date.
/events serves the same purpose as a replication slot in a master → replica setup. Combine /events with our resilient sync process that's always running, and you get a Postgres database with sub-second lag.
This experience is a big contrast to Airtable's. For Airtable, it's actually pretty difficult to see what's changed in a base. First, you have to make requests against each individual table. Given that Airtable's API is limited to 5 requests/second (more below), if you have more than a few tables our dream of sub-second lag time becomes difficult to attain.
Second, deletes are very common in Airtable. And yet, there's no way to easily tell from the API what's been deleted – you have to check every row.
The last curveball is Airtable's inconsistent treatment of the last_updated field for records. For example, changes to computed fields do not affect this timestamp. So, we can't poll for changes to them.
Because of the challenges presented by deletes and computed fields, our sync has to perform a full scan of the Airtable API. This means our lag time is O(N), where N is the size of a given Airtable base.
With Stripe, our lag time is effectively O(1).
Significantly higher API quota
Whereas with Airtable we're limited to 5 requests/second, Stripe grants customers 100 requests/second. This means when you launch a new Stripe database, we can leave half the quota open to you and still backfill 300,000 records per minute.
This helps us deliver a "time to first row" experience that's competitive with querying the API directly. It also means we don't have to worry about 429s/"crowding out" a customer's request quota.
A static schema with an OpenAPI spec
As a flexible datastore/spreadsheet, Airtable's schema can change at any time! This presented some unique design challenges that ended up being blessings in disguise – these challenges helped us build a data-driven, resilient sync for Stripe.
With Airtable, knowledge about a base is contained in a handy /metadata endpoint. This endpoint tells us which tables are in the base and the names and types of the columns for each table.
With Stripe, we drive the sync process off of a single JSON file, itself derived from Stripe's OpenAPI spec. As you can imagine, this spec saved us a tremendous amount of time.
Reads vs writes
Core to our hypothesis is not only that database reads are 10x easier and faster than API reads, but that reads are 10x harder than writes. As stated previously, reads require piecing together bespoke building blocks to formulate your question as an HTTP query. So if your query is "give me all the customers with unpaid invoices over $100", you need to figure out how to express that query in terms of Stripe's API particulars. As reads get more complex, you'll often need to reach for other tricks like caching.
But writes have a low upper-limit to their complexity: "Send along a payload that has this shape. Here are the required fields."
This is why we champion the mantra "read from databases, write to APIs." For reads, we let you skip the API and query your data from SaaS platforms in plain SQL. For writes, a remote procedure call makes sense: you usually want to synchronously verify that the object you're trying to create is valid. You need to pass it through a software validation stack, as often database constraints are not expressive enough.
So, just write to the API, and let those changes flow down to your Sequin database.
To make this architecture great for Airtable was a challenge, as our lag time is O(N). So, you risked the experience where you'd make a write to Airtable's API, yet had to wait several seconds for those changes to show up in your database. So we built a proxy that customers write to Airtable through. When changes are written to Airtable through our proxy, we ensure those changes are written to Airtable and your Sequin database simultaneously.
Because our Stripe sync is so fast, we don't offer a proxy for it just yet. We're planning on instead releasing a synchronization endpoint for customers that want to do read-after-writes with guarantees, eg:
await stripe.markInvoicePaid(invoice);
await fetch("https://api.sequin.io/sync/#{resourceId}", { headers: syncIncHeaders });
let customersPendingInvoices = Customer.joins("invoice").where("invoice.status = 'pending'").order("invoice.created_at desc")
In this semi-pseudocode, on line 1 we make an API request to Stripe to mark an invoice as paid. On line 2, we call the hypothetical Sequin synchronization endpoint. All it does is hold the HTTP request open until your Stripe database is up-to-date. So that way, on line 3, we know we can reload data from the database and be confident the change we made on line 1 will be present.
Assuming your volume of Stripe events is less than ~200-300/s, we'd expect the synchronization endpoint to only hold open for 1-2 seconds.
If this is something you need for your use case, let us know!
More to come
We think a lot about "time to first row" or how long it takes a developer to setup and retrieve the first row of their data from an API platform. If they're querying an API, this means the time it takes for them to get an API token and run their first successful curl request. If they're using Sequin, this is the time it takes for their database to be provisioned and for them to connect with their favorite client and run their first SQL query.
We want to make our databases not only faster and easier to use for complex, mature integrations – but also faster and easier to use from minute 1. A goal approximated by this graph:
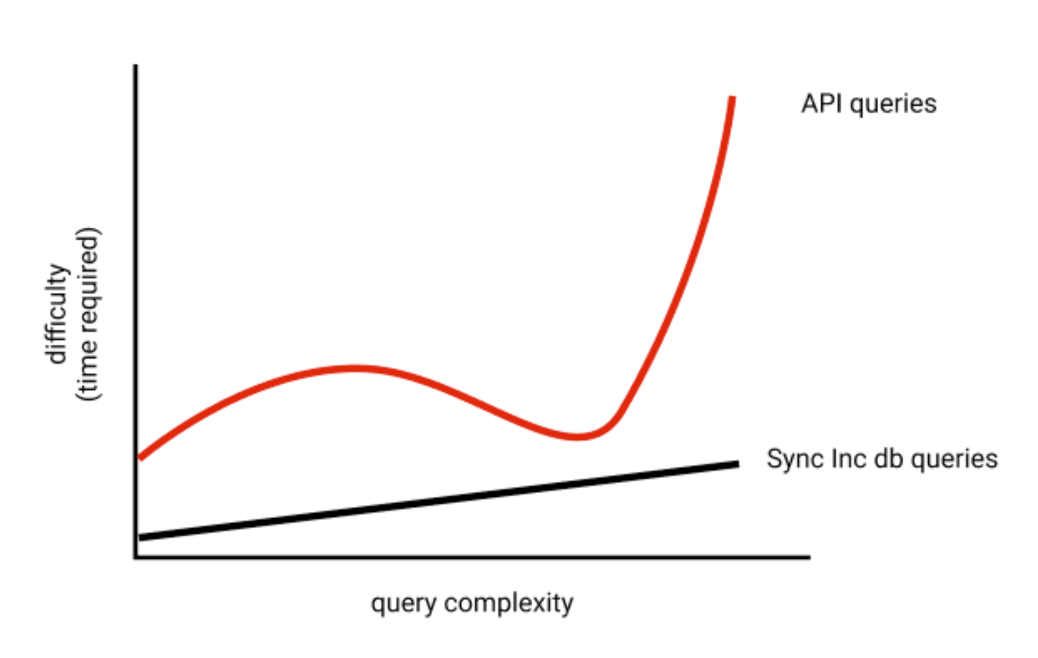
We think great ORM support will be integral to this. With ORM support, developers can query their data across SaaS platforms without ever leaving the comfort of a library they already know.
For Stripe, we also think a lot about how we can help developers quickly explore and grok the data model. Stripe databases currently have 82 tables -- that's a lot to wrap one's head around! In the near term, we'll be releasing sample queries and navigable entity-relationship diagrams to help developers get started. But in the long-term, we want to build an amazing in-browser database explorer that will let developers quickly see the schema of example rows from the most important tables and how those rows relate to one another.
Give it a whirl
It's free to get started with Sequin, no credit card required. And Stripe test accounts are free forever. Give us a whirl and spin up a database of your own! We're here to help if you need anything.