

We’re Sequin. We stream data from services like Salesforce, Stripe, and AWS to messaging systems like Kafka and databases like Postgres. It’s the fastest way to build high-performance integrations you don’t need to worry about. We’re also excited about all the new ML/AI tooling that’s available for developers. One tool, embeddings, lets you search, cluster, and categorize your data in a whole new way.
We ran into a situation the other day that was all too familiar: we needed to write some code that I knew we’ve written before. We wanted to serialize and deserialize an Elixir struct into a Postgres jsonb column. Although we’d solved this before, the module had long been deleted, so it was lingering somewhere in our git history.
We didn’t remember what the module was called, or any other identifying details about the implementation or the commit.
After scraping my mind and scraping through git reflog, we eventually found it. But we realized that simple text search through our git history was too limiting.
It dawned on us that we wanted to perform not a literal string search but a semantic search.
This seemed like the kind of problem that embeddings were designed to solve. So, we set out to build the tool.
Embeddings
An embedding is a vector representation of data. A vector representation is a series of floats, like this:
[-0.016741209, 0.019078454, 0.017176045, -0.028046958, ...]
Embeddings help capture the relatedness of text, images, video, or other data. With that relatedness, you can search, cluster, and classify.
For example, you can generate embeddings for the two strings “I committed my changes to GitHub” and “I pushed the commit to remote.” A literal text comparison would find few substring matches between the two. But an embeddings-powered similarity comparison would rank very high – the two sentences are very related, as they describe practically the same activity.
In contrast, “I’m committed to remote” has many of the same words. But it would rank as not very related. The words “commit” and “remote” are referring to completely different things!
How to create embeddings?
There are lots of ways to create embeddings. The easiest solution is to rely on a third-party vendor like OpenAI:
curl https://api.openai.com/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"input": "Your text string goes here",
"model": "text-embedding-ada-002"
}'
OpenAI accepts batches of embeddings too, where input is set to an array of strings.
Workflow
In order to power a GitHub search tool, first we needed embeddings for all our GitHub data. This means creating string representations of each object and retrieving embeddings via OpenAI’s API.
For example, for Pull Requests, we just concatenated the title and body fields to make the string for embeddings. For commits, we only needed the commit message.
Then, to search across these embeddings, the user will type in a search query. We’d convert the search query into an embedding. Then, with both the search query and GitHub objects represented as embeddings, we can perform our similarity search.
Using Postgres
When generating GitHub embeddings, we need to store them somewhere. This is what a vector database is designed to do: be a repository for your embedding vectors and allow you to perform efficient queries with them.
Fortunately, Postgres has a vector extension, pgvector. This is great because it means you don’t have to add an entirely new data store to your stack. With pgvector, Postgres can work with vector data like embeddings, and it’s performant enough for plenty of workflows like ours.
To add pgvector to your database, you just need to run a single command [1]:
create extension vector;
To build our solution, we knew that we needed to both generate embeddings for all current GitHub data as well as dynamically generate embeddings in the future for all new GitHub data. i.e. we’d need to run some kind of backfill to generate embeddings for all current Pull Requests and Issues. And then setup a process to monitor inserts and updates for these objects to ensure the embeddings are kept up-to-date.
Using Sequin, we pulled all GitHub objects into Postgres. So Pull Requests in GitHub → pull_requests in our database and Issues → issues. We could then run a one-off process that paginated through the table like this:
select id, body, title from github.pull_request order by id asc limit 1000 offset {offset};
Then, for each batch of records, we fetched embeddings with an API request to OpenAI. We decided to store embeddings in a separate table, like this:
create table github_embedding.commit (
id text references github.commit(id) on delete cascade,
embedding vector(1536) not null
)
Batch jobs like this work fine for backfilling data. We knew we could get away with running the task once a day to generate embeddings for new or updated records.
But we wanted our search tool to work with the freshest data possible. We didn’t want to have a big time delay between activity in GitHub and results in the search tool.
Generating embeddings on insert or update
In order to generate embeddings for GitHub objects whenever they were created or updated, we needed a way to find out about these events.
In situations like this, developers often consider Postgres' listen/notify protocol. It's fast to get started with and works great. But, notify events are ephemeral, so delivery is at-most-once. That means there's a risk of missing notifications, and therefore of there being holes in your data.
The other option was to use Sequin’s events. Along with a sync to Postgres, Sequin provides an event stream. Sequin will publish events to a serverless Kafka stream associated with your sync. Sequin will publish events like “GitHub Pull Request deleted” or “GtiHub Commit upserted.”
You don’t have to use Kafka to interface with the event stream. There are options to use a simple HTTP interface or to have events POST’d to an endpoint you choose (webhooks).
Events contain the ID and collection of the affected record, as well as the payload of the record itself:
{
"collection" : "pull_request",
"id":"079013db-8b17-44cd-8528-f5e68fc61333",
"data": {
“activity_date”: “2023-09-12”,
"title" : "Add GitHub embeddings [ … ] ",
// …
}
}
To make events work, we just needed to setup an event listener. That event listener implements a callback function. It derives a string value from the record by concatenating and stringifying fields. Then, it makes a request to OpenAI to get the embedding. Finally, it upserts the embedding into the database:
@impl true
def handle_message(message, state) do
event = Jason.decode!(message.body)
%{ “id” => id, “collection” => collection } = event
body = %{
input: get_embedding_input(collection, id),
model: "text-embedding-ada-002"
}
req =
Req.new(
url: "https://api.openai.com/v1/embeddings",
headers: [
{"Content-Type", "application/json"},
{"Authorization", "Bearer <<secret>>"}
],
json: body
)
{:ok, resp} = Req.post(req)
%{ “data” => [%{ “embedding” => embedding }] } = resp.body
upsert_embedding(collection, id, embedding)
{:ack, state}
end
defp get_embedding_input(“pull_request”, id) do
GitHub.PullRequest.get!(id, select: [:title, :body])
|> Map.take([:title, :body])
|> Enum.join(“; “)
End
defp upsert_embedding(“pull_request”, id, embedding) do
%GitHub.PullRequest{id: id}
|> GitHub.PullRequest.changeset(%{ embedding: embedding })
|> MyApp.Repo.insert!(on_conflict: :replace_all, conflict_target: [:id])
end
# handle other collection types here
With the backfill done and an event handler in place, we now had up-to-date database tables with GitHub embeddings. With that foundation in place, we were ready to build our tool!
A Postgres query for finding matches
With your embeddings setup in Postgres, you’re ready to create a mechanism for querying them.
Supabase has a great post on embeddings in Postgres. I’ve adapted their similarity query below. You can use the cosine distance operator (<=>) provided by pg_vector to determine similarity. Here’s a query that grabs a list of pull_requests over a match_threshold, ordered by most similar to least similar:
select
pull_request.id,
pull_request.title,
pull_request.body,
1 - (embedding_pull_request.embedding <=> {{searchEmbedding.value}}) as similarity
from github_sequin.pull_request as pull_request
join github_embedding_sequin.pull_request as embedding_pull_request on pull_request.id = embedding_pull_request.id
-- match threshold set to 0.75, you can change it
where 1 - (embedding_pull_request.embedding <=> {{searchEmbedding.value}}) > 0.75
order by similarity desc
-- match count set to 5, you can change it
limit 5;
The search tool
With our data model and search function squared away, we were ready to build our tool.
When the user enters a query, we first convert their search query into an embedding using OpenAI. Then, we use the SQL query above to find the GitHub objects that are the closest match.
Below is a simple example of this tool. Here’s a demonstration of a search for Pull Requests that mention “serialize and deserialize structs into jsonb ecto”:
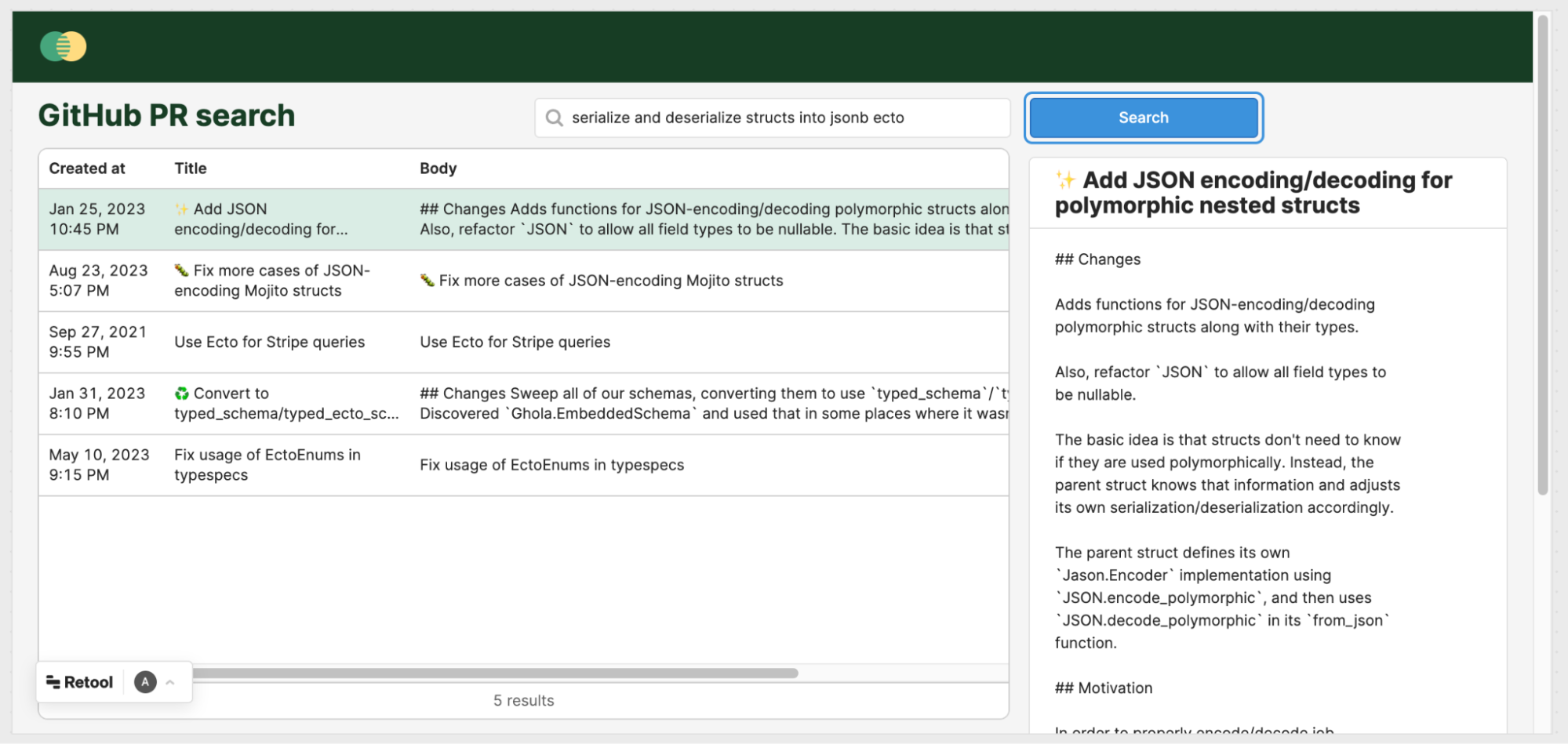
On the left, we see the list of the top 5 PRs that matched, sorted by similarity descending. On the right is a preview of the PR that you selected.
Note that this is not a literal string match. The search refers to the “serialize and deserialize errors,” but the PR contains serializes/deserializes. The PR also doesn’t mention jsonb, just JSON.
Because of embeddings, we found the exact PR we were looking for, and with only a vague idea of what we were looking for!
Weaknesses
The tool is very effective when the search query has some substance to it (several words) and your PRs do as well. Naturally, if a PR or issue is very light on content, it’s harder to match.
In fact, PRs or issues with very little text content can match too frequently for the wrong things. So, you may consider adding a clause that filters out GitHub objects that have fields that don’t meet some minimum required length.
Remember, you’re not describing what you’re looking for. You’re writing text that you think will be a match for a description found in a PR or an issue.
Further exploration
Now that we have our first workflow around embeddings, we’re starting to think up other ideas.
For example, how could we expand search over commit bodies/diffs? Will embeddings work well if we’re describing the code inside of a commit (vs matching descriptions on the PRs and issues around the code)?
Can we power roll-ups off this data? For example, imagine a weekly summary that describes what got committed (vs just listing PRs). Or reports like “cluster analysis” that told the team how our time broke down between fixing bugs vs shipping new features.
pg_vectoris included in most of the latest distributions of Postgres.If you're on AWS RDS, be sure you upgrade to Postgres 15.2+ to get access to the
vectorextension. ↩︎